
一到年关,最不缺的就是各种盘点总结了。
这不,中国机构实现了 7 分钟完成 30X 测序深度人类全基因组测序的成绩,时隔 3 个月又被提了起来。

听不懂没关系,我们只需要知道,这个成就意味着基因筛查将有可能进入常规体检项,遗传病检查也可能像咽拭子检测一样立等可取了。
比如镰刀型贫血症、先天性心脏病等所有由于基因异常引起的疾病,都可以通过基因检测的方式早发现早预防早治疗,特别是在生育健康方面意义重大。

但是目前的基因检查项目大多只针对常见遗传病做筛查,一些罕见的遗传病很难被检测到。并且检测机构出具报告一般都需要 20 天以上,检测项目周期太长。
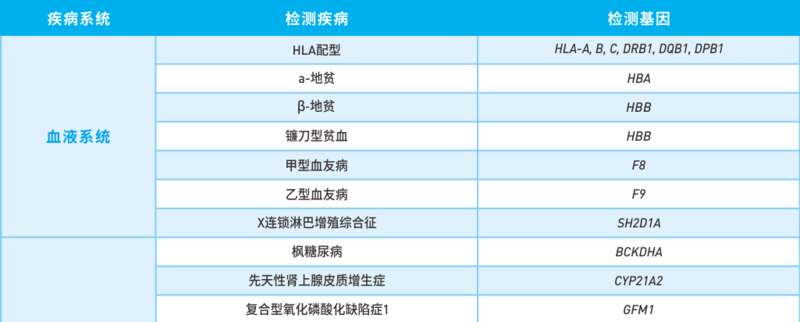
华大医学单基因遗传病检测的部分项目。▼
中国团队把人类全基因组测序所需要的时间,直接压缩到了 7 分钟,相当于给生物学界开通了一辆和谐号,得到生物的全部遗传信息,那都是分分钟的事。

想知道 7 分钟的意义有多大,那就先来搞清楚全基因组测序是什么吧。
基因测序就是把 DNA 信息转换成人类可读取的数字信息过程,而全基因组测序,就是把生物的所有 DNA 信息全部转化为数字信息。
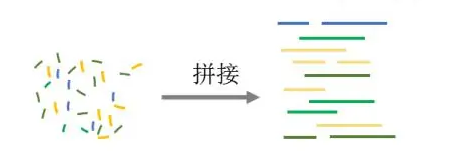
读取一整条 DNA 链的碱基排列信息,不仅速度慢,而且很容易出错。在实际操作过程中,DNA 长链会被切割成许许多多的小片段并同时进行测序,这样可以大大减少测序时间。
虽然小片段序列信息的获取更快更容易,但是这也带来了一个新难题,如何把这些小片段正确拼接还原成完整序列?


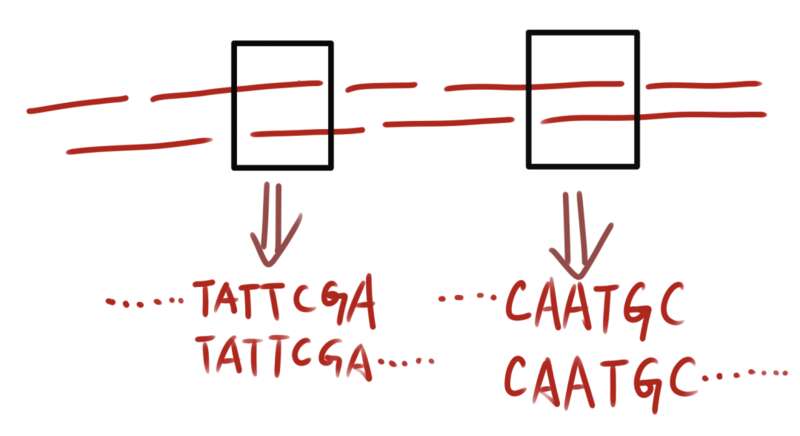
玩过拼图的人都知道,判断两块零片是不是相邻位置,需要参考它们的图案有没有很好地吻合在一起。
拼接 DNA 片段也一样,两条片段是不是相邻位置,要看它们末端的序列能不能完全重叠。
只要两条序列首尾两端分别存在相同的序列,这两段序列就可以合并成一段。

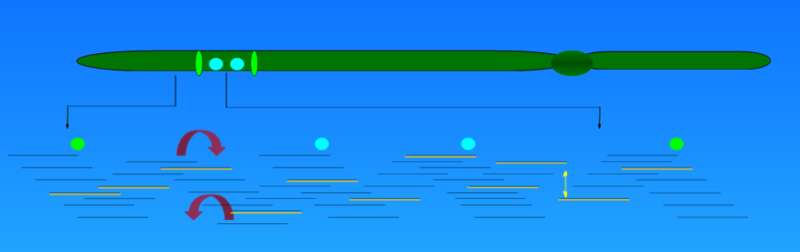
当然了,这是运气好的情况,两段相邻片段可以顺利找得出来。如果运气不好的话,在某一处断点就有可能找不到和它吻合的片段。
为了保证测序片段能够覆盖整个基因序列,常用的手段只有以量取胜。把十几倍几十倍的片段往模版里填,如果还存在填不上空的情况就该去买彩票了。
但是片段数量的翻倍直接导致的后果就是拼接工作量的指数增加,毕竟拼 1000 块拼图花费的时间可不止是 100 块拼图的十倍。
这个工作量有多大呢?我们放在具体的测序案例中计算一下。

以人类全基因组测序为例,人类有 23 对染色体共 3.2Gb 碱基对数据,一般测序的片段大小会选择在 150-350bp 范围内,也就是说,对人类基因组测序至少需要处理 10000000 的片段数量。
而为了提高测序准确率和覆盖度,片段的序列数据一般会远超基因组数据。比如常用的 30X 测序深度,测序得到的总数据达到了基因组数据的 30 倍,序列数量大约增加到了 300000000 段。
粗略估算一下,数据读取 300000000 次才能组装好一对小片段,第二次组装则需要至少再读取 150000000 次,以此类推。
对数据读取次数有了概念,我们再换算一下数据的内存占用量。据不准确计算,1bp 碱基大概占用 3B 内存,那么 30X 测序深度的人类全基因组大概需要占用接近 300GB 内存。

别说读取分析数据了,光是存起来就足够把计算机搞死机了,所以这样的任务一般都交给专业测序公司强大的服务器来做。而业界目前的水平,完成人类全基因组的拼接至少需要 24 个小时。

这样一对比, 7 分钟能完成 24 小时的海量数据处理工作,确实强得一批。难道是超级 CPU 出现了?

CPU 还是那些 CPU,不过是有新的数据处理方式出现了。
我们把数据读写看作是往仓库里运包裹,大大小小各种包裹都要往里装,无论物件大小全部按顺序摆放的方式,不仅搬运效率低,空间利用率也不高。
正确的方法是将小包裹收纳打包进大箱子,再和其他大包裹一起顺序摆放,不仅提高了整体的空间利用率,也缩减了搬运时间。

这就是 7 分钟办完 24 小时工作的原因之一,大数据直接写入,小文件聚合成大文件再写入,不仅存得快,还存得多。

海量数据秒处理的另一个秘诀就是 “ 天下大同 ” 。
通常情况下,不同类型的数据互相不认识,需要借助单独的协议进行私密对话,调用上不太方便。
想提高数据的调用效率,那就让它们都来广场上喊话好了,露天场地找人总比在小区里挨家挨户找人要快得多。
只要打破不同数据间的加解密逻辑,使用统一的数据访问协议,免去加载过程,就可以实现对磁盘内所有数据的快速调用。
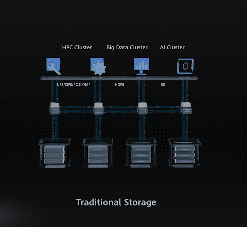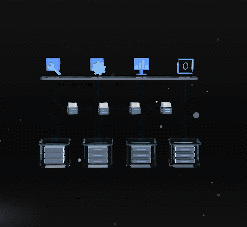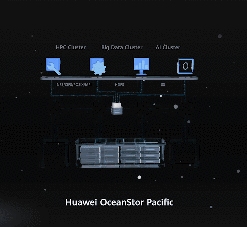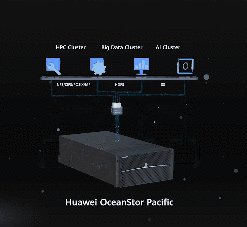
除了这两项突破性的数据处理方式,一些硬件软件上的加强也促成了这项 7 分钟的成就。
比如说压缩磁盘大小,改造服务器结构,用相同体积放置更多数量的固态硬盘,实现更大容量的数据存储功能。

另外该平台还开发出了多线操作的数据读写模式,能够把处理数据的速度再提升一级;并且还改进了数据压缩算法,能够以更小的磁盘容量处理更多的数据。
种种创新技术的强强联合实现了海量数据分析 24 小时到 7 分钟的飞跃。连天文数字规模的生物信息都能在几分钟时间内进行处理,还有什么做不到的呢。
这个 7 分钟的意义不仅仅是快速获得全部基因信息,也是数据处理领域中十分重要的一项突破。
类似一些需要精密计算并且数据量庞大的应用领域,用上中国自己的服务器来处理,又快又安全。
例如卫星遥感,药物研发,能源勘测等,都需要对海量数据进行分析;而自动驾驶之类的技术则要求了数据的实时反馈,数据的高速运算处理能力必不可少。
换句话说,驯服了数据就相当于把握住了科技命脉,得数据者得天下。依附在这个基础上的所有领域,都得铆足了劲再卷一波。
说不定,一直以来磕磕绊绊的 AR 眼镜,很快就可以普及了。


